











Best computer science schools ranked by boba
Many people underestimate the importance of boba when they choose grad school. For those who don't know what boba is ...

I'm Boyuan Chen (陈博远), an AI researcher and roboticist at MIT. I am currently a third year PhD student working with Prof. Vincent Sitzmann and Prof. Russ Tedrake. I am interested in foundation models for decision making. I work on building world models that allow AI agents to aquire skills via both search (like AlphaGo) and policy (like GPT). I am also interested in deploying these models on real-world robots, aka embodied intelligence. Outside research, building robots is my long-time hobby. Scroll down to see some of my robots!
Previosuly, I interned at Google Deepmind and Google X. I obtained my bachelor's degree in computer science and math at UC Berkeley, where I spent a signficant amount of time doing research at Berkeley Artificial Intelligence Research (BAIR) on deep reinforcement learning and unsupervised learning. I also spent a year studying philosophy during my undergrad. I am a big fan of chess, robots and boba.

This paper presents Diffusion Forcing, a new training paradigm where a diffusion model is trained to denoise a set of tokens with independent per-token noise levels. We apply Diffusion Forcing to sequence generative modeling by training a causal next-token prediction model to generate one or several future tokens without fully diffusing past ones. Our approach is shown to combine the strengths of next-token prediction models, such as variable-length generation, with the strengths of full-sequence diffusion models, such as the ability to guide sampling to desirable trajectories. Our method offers a range of additional capabilities, such as (1) rolling-out sequences of continuous tokens, such as video, with lengths past the training horizon, where baselines diverge and (2) new sampling and guiding schemes that uniquely profit from Diffusion Forcing's variable-horizon and causal architecture, and which lead to marked performance gains in decision-making and planning tasks. In addition to its empirical success, our method is proven to optimize a variational lower bound on the likelihoods of all subsequences of tokens drawn from the true joint distribution.

Robot co-design, where the morphology of a robot is optimized jointly with a learned policy to solve a specific task, is an emerging area of research. It holds particular promise for soft robots, which are amenable to novel manufacturing techniques that can realize learned morphologies and actuators. Inspired by nature and recent novel robot designs, we propose to go a step further and explore the novel reconfigurable robots, defined as robots that can change their morphology within their lifetime. We formalize control of reconfigurable soft robots as a highdimensional reinforcement learning (RL) problem. We unify morphology change, locomotion, and environment interaction in the same action space, and introduce an appropriate, coarse-to-fine curriculum that enables us to discover policies that accomplish fine-grained control of the resulting robots. We also introduce DittoGym, a comprehensive RL benchmark for reconfigurable soft robots that require fine-grained morphology changes to accomplish the tasks. Finally, we evaluate our proposed coarse-to-fine algorithm on DittoGym and demonstrate robots that learn to change their morphology several times within a sequence, uniquely enabled by our RL algorithm.

Understanding and reasoning about spatial relationships is a fundamental capability for Visual Question Answering (VQA) and robotics. While Vision Language Models (VLM) have demonstrated remarkable performance in certain VQA benchmarks, they still lack capabilities in 3D spatial reasoning, such as recognizing quantitative relationships of physical objects like distances or size differences. We hypothesize that VLMs' limited spatial reasoning capability is due to the lack of 3D spatial knowledge in training data and aim to solve this problem by training VLMs with Internet-scale spatial reasoning data. To this end, we present a system to facilitate this approach. We first develop an automatic 3D spatial VQA data generation framework that scales up to 2 billion VQA examples on 10 million real-world images. We then investigate various factors in the training recipe, including data quality, training pipeline, and VLM architecture. Our work features the first internet-scale 3D spatial reasoning dataset in metric space. By training a VLM on such data, we significantly enhance its ability on both qualitative and quantitative spatial VQA. Finally, we demonstrate that this VLM unlocks novel downstream applications in chain-of-thought spatial reasoning and robotics due to its quantitative estimation capability.
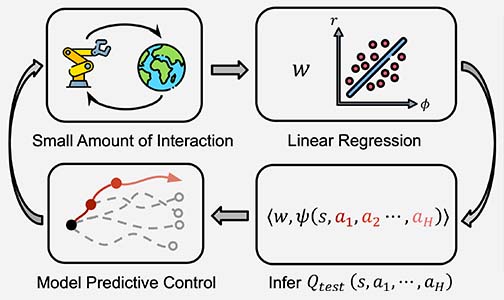
Reinforcement learning (RL) algorithms have the potential not only for synthesizing complex control behaviors, but also for transfer across tasks. Model-free RL excels in solving problems with high-dimensional observations or long horizons, but the learned policies do not transfer across different reward functions. Model-based RL, on the other hand, naturally enables transfer across different reward functions, but struggles in complex environments due to compounding error. In this work, we propose a new method for transferring behaviors across tasks with different rewards, combining the performance of model-free RL with the transferability of model-based RL. In particular, we show how model-free RL using a number of random features as the reward allows for implicit modeling of long-horizon environment dynamics. Model-predictive control using these implicit models enables fast adaptation to problems with new reward functions while avoiding the compounding error from model rollouts. Our method can be trained on offline datasets without reward labels, and quickly deployed on new tasks, making it more widely applicable than typical RL methods. We validate that our proposed method enables transfer across tasks on a variety of manipulation and locomotion domains.
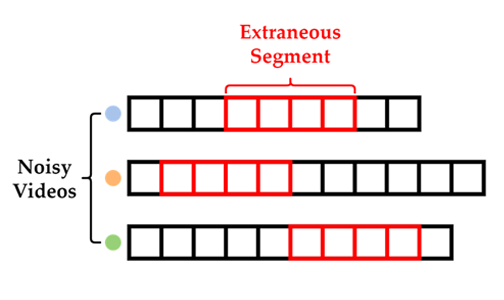
Visual imitation learning provides an effective framework to learn skills from demonstrations. However, the quality of the provided demonstrations usually significantly affects the ability of an agent to acquire desired skills. Therefore, the standard visual imitation learning assumes near-optimal demonstrations, which are expensive or sometimes prohibitive to collect. Previous works propose to learn from noisy demonstrations; however, the noise is usually assumed to follow a context-independent distribution such as a uniform or gaussian distribution. In this paper, we consider another crucial yet underexplored setting — imitation learning with task-irrelevant yet locally consistent segments in the demonstrations (e.g., wiping sweat while cutting potatoes in a cooking tutorial). We argue that such noise is common in real world data and term them as “extraneous” segments. To tackle this problem, we introduce Extraneousness-Aware Imitation Learning (EIL), a self-supervised approach that learns visuomotor policies from third-person demonstrations with extraneous subsequences. EIL learns action-conditioned observation embeddings in a self-supervised manner and retrieves task-relevant observations across visual demonstrations while excluding the extraneous ones. Experimental results show that EIL outperforms strong baselines and achieves comparable policies to those trained with perfect demonstration on both simulated and real-world robot control tasks.
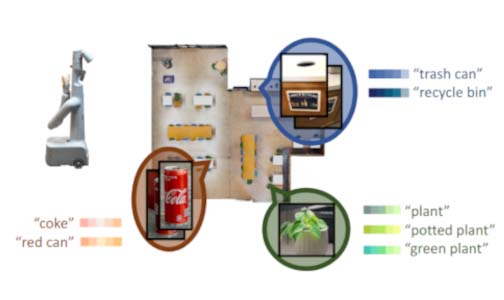
Large language models (LLMs) have unlocked new capabilities of task planning from human instructions. However, prior attempts to apply LLMs to real-world robotic tasks are limited by the lack of grounding in the surrounding scene. In this paper, we develop NLMap, an open-vocabulary and queryable scene representation to address this problem. NLMap serves as a framework to gather and integrate contextual information into LLM planners, allowing them to see and query available objects in the scene before generating a context-conditioned plan. NLMap first establishes a natural language queryable scene representation with Visual Language models (VLMs). An LLM based object proposal module parses instructions and proposes involved objects to query the scene representation for object availability and location. An LLM planner then plans with such information about the scene. NLMap allows robots to operate without a fixed list of objects nor executable options, enabling real robot operation unachievable by previous methods.

Learning sensorimotor control policies from high-dimensional images crucially relies on the quality of the underlying visual representations. Prior works show that structured latent space such as visual keypoints often outperforms unstructured representations for robotic control. However, most of these representations, whether structured or unstructured are learned in a 2D space even though the control tasks are usually performed in a 3D environment. In this work, we propose a framework to learn such a 3D geometric structure directly from images in an end-to-end unsupervised manner. The input images are embedded into latent 3D keypoints via a differentiable encoder which is trained to optimize both a multi-view consistency loss and downstream task objective. These discovered 3D keypoints tend to meaningfully capture robot joints as well as object movements in a consistent manner across both time and 3D space. The proposed approach outperforms prior state-of-art methods across a variety of reinforcement learning benchmarks.

It is a long-standing challenge to enable an intelligent agent to learn in one environment and generalize to an unseen environment without further data collection and finetuning. In this paper, we consider a zero shot generalization problem setup that complies with biological intelligent agents' learning and generalization processes. The agent is first presented with previous experiences in the training environment, along with task description in the form of trajectory-level sparse rewards. Later when it is placed in the new testing environment, it is asked to perform the task without any interaction with the testing environment. We find this setting natural for biological creatures and at the same time, challenging for previous methods. Behavior cloning, state-of-art RL along with other zero-shot learning methods perform poorly on this benchmark. Given a set of experiences in the training environment, our method learns a neural function that decomposes the sparse reward into particular regions in a contingency-aware observation as a per step reward. Based on such decomposed rewards, we further learn a dynamics model and use Model Predictive Control (MPC) to obtain a policy. Since the rewards are decomposed to finer-granularity observations, they are naturally generalizable to new environments that are composed of similar basic elements. We demonstrate our method on a wide range of environments, including a classic video game -- Super Mario Bros, as well as a robotic continuous control task. Please refer to the project page for more visualized results.
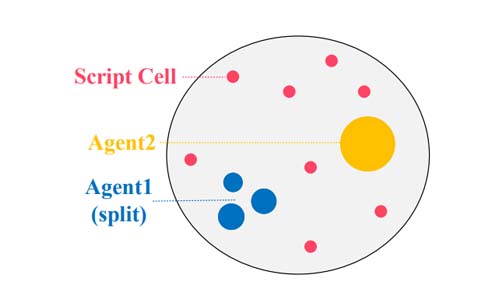
We propose a simple, general and effective technique, Reward Randomization for discovering diverse strategic policies in complex multi-agent games. Combining reward randomization and policy gradient, we derive a new algorithm, Reward-Randomized Policy Gradient (RPG). RPG is able to discover multiple distinctive human-interpretable strategies in challenging temporal trust dilemmas, including grid-world games(MonsterHunt and Escalation) and a real-world web game Agar.io, where multiple equilibria exist but standard multi-agent policy gradient algorithms always converge to a fixed one with a sub-optimal payoff for every player even using state-of-the-art exploration techniques (including RND, DIAYN, MAVEN). Furthermore, with the set of diverse strategies from RPG, we can (1) achieve higher payoffs by fine-tuning the best policy from the set; and (2) obtain an adaptive agent by using this set of strategies as its training opponents.










Many people underestimate the importance of boba when they choose grad school. For those who don't know what boba is ...

以ChatGPT为代表的大模型让我们瞥见了未来的一隅。机器人大模型在过去一年里出现在了几乎每一个机器人公司的PPT里。那么大语言模型的思路会给我们带通用机器人么? ...

ChatGPT has given us a glimpse of the future. So, will the same bring us general-purpose robots? ...
Many people underestimate the importance of boba when they choose grad school. For those who don't know what boba is ...
以ChatGPT为代表的大模型让我们瞥见了未来的一隅。机器人大模型在过去一年里出现在了几乎每一个机器人公司的PPT里。那么大语言模型的思路会给我们带通用机器人么? ...
ChatGPT has given us a glimpse of the future. So, will the same bring us general-purpose robots? ...
Many people underestimate the importance of boba when they choose grad school. For those who don't know what boba is ...
以ChatGPT为代表的大模型让我们瞥见了未来的一隅。机器人大模型在过去一年里出现在了几乎每一个机器人公司的PPT里。那么大语言模型的思路会给我们带通用机器人么? ...
ChatGPT has given us a glimpse of the future. So, will the same bring us general-purpose robots? ...